
Google為自己的業(yè)務(wù)需要提出了編程模型MapReduce和分布式文件系統(tǒng)Google File System,并發(fā)布了相關(guān)論文(可在Google Research的網(wǎng)站上獲得: GFS 、 MapReduce)。 Doug Cutting和Mike Cafarella在開發(fā)搜索引擎Nutch時對這兩篇論文做了自己的實現(xiàn),即同名的MapReduce和HDFS,合起來就是Hadoop。
MapReduce的Data flow如下圖,原始數(shù)據(jù)經(jīng)過mapper處理,再進(jìn)行partition和sort,到達(dá)reducer,輸出最后結(jié)果。
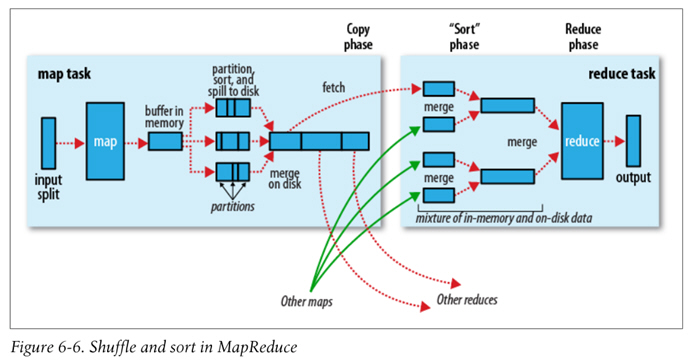
圖片來自Hadoop: The Definitive Guide
Hadoop Streaming原理
Hadoop本身是用Java開發(fā)的,程序也需要用Java編寫,但是通過Hadoop Streaming,我們可以使用任意語言來編寫程序,讓Hadoop運(yùn)行。
Hadoop Streaming的相關(guān)源代碼可以在Hadoop的Github repo 查看。簡單來說,就是通過將用其他語言編寫的mapper和reducer通過參數(shù)傳給一個事先寫好的Java程序(Hadoop自帶的*-streaming.jar),這個Java程序會負(fù)責(zé)創(chuàng)建MR作業(yè),另開一個進(jìn)程來運(yùn)行mapper,將得到的輸入通過stdin傳給它,再將mapper處理后輸出到stdout的數(shù)據(jù)交給Hadoop,partition和sort之后,再另開進(jìn)程運(yùn)行reducer,同樣地通過stdin/stdout得到最終結(jié)果。因此,我們只需要在其他語言編寫的程序里,通過stdin接收數(shù)據(jù),再將處理過的數(shù)據(jù)輸出到stdout,Hadoop streaming就能通過這個Java的wrapper幫我們解決中間繁瑣的步驟,運(yùn)行分布式程序。
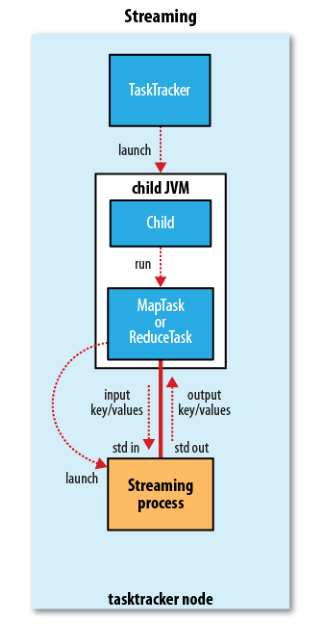
圖片來自Hadoop: The Definitive Guide
原理上只要是能夠處理stdio的語言都能用來寫mapper和reducer,也可以指定mapper或reducer為Linux下的程序(如awk、grep、cat)或者按照一定格式寫好的java class。因此,mapper和reducer也不必是同一類的程序。
Hadoop Streaming的優(yōu)缺點
優(yōu)點
可以使用自己喜歡的語言來編寫MapReduce程序(換句話說,不必寫Java XD)
不需要像寫Java的MR程序那樣import一大堆庫,在代碼里做一大堆配置,很多東西都抽象到了stdio上,代碼量顯著減少
因為沒有庫的依賴,調(diào)試方便,并且可以脫離Hadoop先在本地用管道模擬調(diào)試
缺點
只能通過命令行參數(shù)來控制MapReduce框架,不像Java的程序那樣可以在代碼里使用API,控制力比較弱,有些東西鞭長莫及
因為中間隔著一層處理,效率會比較慢
所以Hadoop Streaming比較適合做一些簡單的任務(wù),比如用python寫只有一兩百行的腳本。如果項目比較復(fù)雜,或者需要進(jìn)行比較細(xì)致的優(yōu)化,使用Streaming就容易出現(xiàn)一些束手束腳的地方。
用python編寫簡單的Hadoop Streaming程序
這里提供兩個例子:
Michael Noll的word count程序
Hadoop: The Definitive Guide里的例程
使用python編寫Hadoop Streaming程序有幾點需要注意:
在能使用iterator的情況下,盡量使用iterator,避免將stdin的輸入大量儲存在內(nèi)存里,否則會嚴(yán)重降低性能
streaming不會幫你分割key和value傳進(jìn)來,傳進(jìn)來的只是一個個字符串而已,需要你自己在代碼里手動調(diào)用split()
從stdin得到的每一行數(shù)據(jù)末尾似乎會有 ,保險起見一般都需要使用rstrip()來去掉
在想獲得K-V list而不是一個個處理key-value pair時,可以使用groupby配合itemgetter將key相同的k-v pair組成一個個group,得到類似Java編寫的reduce可以直接獲取一個Text類型的key和一個iterable作為value的效果。注意itemgetter的效率比lambda表達(dá)式要高,所以如果需求不是很復(fù)雜的話,盡量用itemgetter比較好。
我在編寫Hadoop Streaming程序時的基本模版是
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Some description here...
"""
import sys
from operator import itemgetter
from itertools import groupby
def read_input(file):
"""Read input and split."""
for line in file:
yield line.rstrip().split(' ')
def main():
data = read_input(sys.stdin)
for key, kviter in groupby(data, itemgetter(0)):
# some code here..
if __name__ == "__main__":
main()
如果對輸入輸出格式有不同于默認(rèn)的控制,主要會在read_input()里調(diào)整。
本地調(diào)試
本地調(diào)試用于Hadoop Streaming的python程序的基本模式是:
$ cat | python| sort -t $' ' -k1,1 | python >
或者如果不想用多余的cat,也可以用<定向
$ python< | sort -t $' ' -k1,1 | python >
這里有幾點需要注意:
Hadoop默認(rèn)按照tab來分割key和value,以第一個分割出的部分為key,按key進(jìn)行排序,因此這里使用
sort -t $' ' -k1,1
來模擬。如果你有其他需求,在交給Hadoop Streaming執(zhí)行時可以通過命令行參數(shù)調(diào),本地調(diào)試也可以進(jìn)行相應(yīng)的調(diào)整,主要是調(diào)整sort的參數(shù)。因此為了能夠熟練進(jìn)行本地調(diào)試,建議先掌握sort命令的用法。
如果你在python腳本里加上了shebang,并且為它們添加了執(zhí)行權(quán)限,也可以用類似于
./mapper.py
來代替
python mapper.py
聲明:本網(wǎng)頁內(nèi)容旨在傳播知識,若有侵權(quán)等問題請及時與本網(wǎng)聯(lián)系,我們將在第一時間刪除處理。TEL:177 7030 7066 E-MAIL:11247931@qq.com
Copyright ? 2019-2025 51dongshi.com 版權(quán)所有
違法及侵權(quán)請聯(lián)系:TEL:177 7030 7066 E-MAIL:11247931@qq.com 本站由北京市萬商天勤律師事務(wù)所王興未律師提供法律服務(wù)


